
Sumber: Heart of the Machine
Artikel ini adalah tentang 2271 kata , Dianjurkan untuk membaca 5 menit
Artikel ini mengatur konten entri blog, dan pembaca dapat memahami pembelajaran algoritme mesin yang tampaknya canggih berdasarkan gambar-gambar ini.

Topik pembelajaran mesin telah menjadi sangat umum, semua orang membicarakannya, tetapi hanya sedikit orang yang dapat memahaminya secara menyeluruh. Beberapa artikel pembelajaran mesin saat ini di Internet tidak jelas, terlalu teoretis, atau mencakup keajaiban kecerdasan buatan, ilmu data, dan pekerjaan di masa depan.
Oleh karena itu penulis artikel vas3k ini memudahkan pembaca untuk memahami pembelajaran mesin melalui bahasa yang ringkas dan konten grafis yang jelas. Selain pengenalan teoritis yang tidak jelas dan sulit, artikel ini berfokus pada masalah praktis dalam pembelajaran mesin, solusi efektif, dan teori yang mudah dipahami. Apakah Anda seorang programmer atau manajer, artikel ini cocok untuk Anda.
Ruang lingkup AI
Bidang apa yang disertakan AI, dan apa hubungan antara AI dan berbagai istilah teknis? Faktanya, kami memiliki beberapa metode penilaian, dan pembagian kategori AI tidak akan unik. Misalnya, pengetahuan yang paling "umum" dapat dilihat pada gambar di bawah.
Anda mungkin berpikir:
- Kecerdasan buatan adalah bidang pengetahuan yang lengkap, mirip dengan biologi atau kimia;
- Pembelajaran mesin adalah bagian yang sangat penting dari kecerdasan buatan, tetapi ini bukan satu-satunya bagian;
- Jaringan saraf adalah jenis pembelajaran mesin, yang sangat populer sekarang, tetapi masih ada algoritme luar biasa lainnya;

Tapi, apakah pembelajaran mendalam semua jaringan saraf? Jelasnya belum tentu, misalnya, hutan dalam di Zhou Zhihua, yang merupakan model pembelajaran mendalam pertama berdasarkan komponen yang tidak dapat dibedakan. Oleh karena itu, divisi yang lebih ilmiah mungkin ada di buku bunga di bawah ini:

Pembelajaran mesin di bawah ini harus menjadi pembelajaran representasi, yang merangkum semua metode penggunaan pembelajaran mesin untuk menambang representasi itu sendiri. Dibandingkan dengan ML tradisional, yang memerlukan desain fitur data manual, metode ini dapat mempelajari fitur data yang berguna sendiri. Keseluruhan deep learning juga merupakan jenis pembelajaran representasi, yang membangun representasi kompleks dari representasi sederhana melalui model berlapis.
Peta jalan pembelajaran mesin
Jika Anda malas, berikut adalah roadmap teknis lengkap untuk referensi Anda.

Menurut klasifikasi utama saat ini, pembelajaran mesin sebagian besar dibagi menjadi empat kategori:
- Pembelajaran mesin klasik;
- Pembelajaran penguatan
- Jaringan saraf dan pembelajaran mendalam;
- Metode integrasi
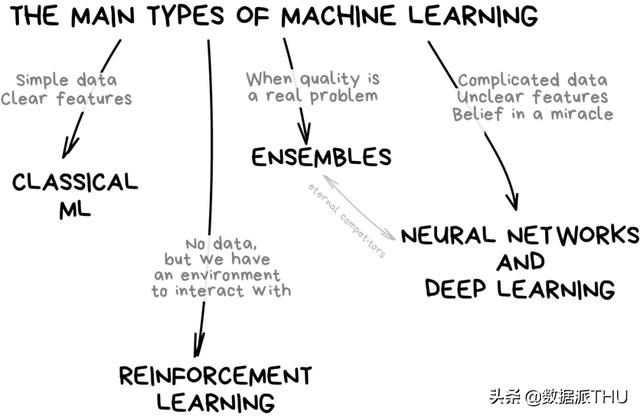
Pembelajaran mesin klasik
Pembelajaran mesin klasik sering kali dibagi menjadi dua kategori: pembelajaran yang diawasi dan pembelajaran tanpa pengawasan.
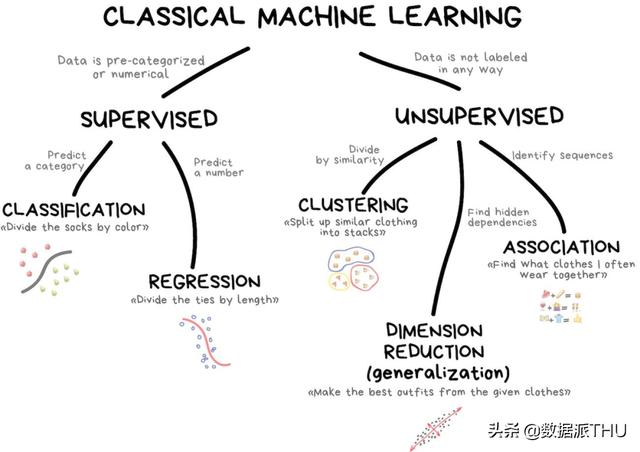
Pembelajaran yang diawasi
Dalam klasifikasi, model selalu membutuhkan tutor, yaitu anotasi fitur yang sesuai, sehingga mesin dapat melakukan klasifikasi lebih lanjut berdasarkan pembelajaran anotasi ini. Semuanya bisa diklasifikasikan, mengelompokkan pengguna berdasarkan minat, mengelompokkan artikel berdasarkan bahasa dan topik, mengelompokkan musik berdasarkan genre, dan mengelompokkan email berdasarkan kata kunci.
Dalam pemfilteran spam, algoritma Naive Bayes telah digunakan secara luas. Faktanya, Naive Bayes pernah dianggap sebagai algoritma paling elegan dan praktis.

Support vector machine (SVM) adalah metode klasifikasi klasik paling populer. Ini juga digunakan untuk mengklasifikasikan semua yang ada: penampilan tanaman di foto, dokumen, dll. Ide di balik mesin vektor pendukung juga sangat sederhana, ambil gambar berikut sebagai contoh, ia mencoba menggambar dua garis dengan margin terbesar di antara titik data.

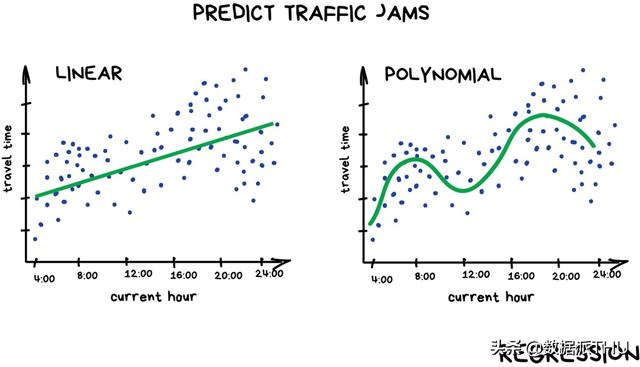
Regresi pembelajaran yang diawasi
Regresi pada dasarnya adalah klasifikasi, tetapi subjek prediksi adalah angka, bukan kategori. Misalnya, harga mobil dihitung berdasarkan jarak tempuh, lalu lintas dihitung berdasarkan waktu, permintaan pasar dihitung berdasarkan pertumbuhan perusahaan, dll. Ketika ramalan bergantung pada waktu, regresi adalah pilihan yang sangat cocok.
Pembelajaran tanpa pengawasan
Pembelajaran tanpa pengawasan baru ditemukan pada 1990-an. Ini dapat digambarkan sebagai "menyegmentasikan target berdasarkan fitur yang tidak diketahui, dan mesin memilih cara terbaik."
Pengelompokan pembelajaran tanpa pengawasan
Clustering adalah klasifikasi tanpa kelas yang telah ditentukan sebelumnya. Misalnya, jika Anda tidak ingat semua warna Anda, klasifikasikan kaus kaki berdasarkan warnanya. Algoritme pengelompokan mencoba menemukan objek serupa melalui fitur tertentu dan menggabungkannya ke dalam kluster.

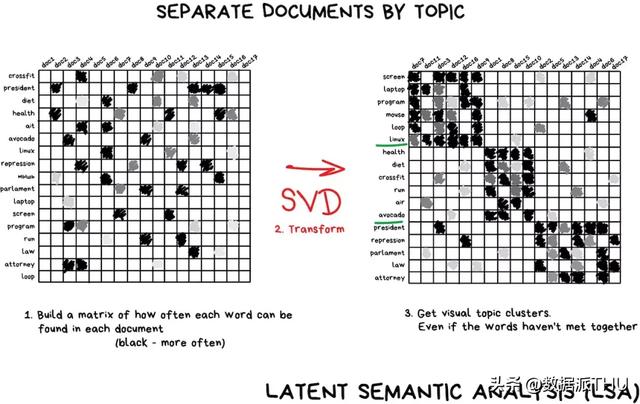
Pengurangan dimensi pembelajaran tanpa pengawasan
Orang selalu lebih nyaman menggunakan hal-hal abstrak daripada fitur yang terpisah-pisah. Misalnya, gabungkan semua anjing dengan telinga segitiga, hidung panjang, dan ekor besar menjadi konsep abstrak yang baik- "anjing gembala".
Contoh lainnya adalah artikel tentang sains dan teknologi memiliki istilah yang lebih teknis, dan nama politisi adalah yang paling umum dalam berita politik. Jika kita ingin kata-kata dan artikel karakteristik ini membentuk fitur baru untuk mempertahankan relevansinya, SVD adalah pilihan yang baik.
Pembelajaran aturan asosiasi pembelajaran yang tidak diawasi
Termasuk analisis keranjang belanja, strategi pemasaran otomatis, dll. Misalnya, jika seorang pelanggan berjalan ke kasir dengan enam botol bir, haruskah dia menaruh kacang dalam perjalanannya? Jika dirilis, seberapa sering pelanggan ini datang untuk membeli? Jika kacang bir adalah pasangan yang cocok, hal-hal lain apa yang bisa cocok seperti ini?

Dalam kehidupan nyata, setiap pengecer besar memiliki solusi khusus, dan yang paling maju secara teknologi adalah "sistem rekomendasi" tersebut.
Metode integrasi
"Persatuan adalah kekuatan", pepatah lama ini dengan tepat mengungkapkan ide dasar "metode terintegrasi" di bidang pembelajaran mesin. Dalam metode ensembel, kami biasanya melatih beberapa "model lemah" dengan harapan dapat digabungkan menjadi metode yang ampuh. Seperti berbagai kompetisi ML klasik, yang memiliki hasil hampir terbaik, seperti pohon penambah gradien, hutan acak, dll., Semuanya merupakan metode terintegrasi.
Secara umum, "metode kombinasi" dari metode integrasi dapat dibagi menjadi tiga jenis utama: Stacking, Bagging, dan Boosting.
Seperti yang ditunjukkan pada gambar di bawah, Stacking biasanya menganggap pelajar lemah yang heterogen. Pelajar yang lemah dapat dilatih secara paralel terlebih dahulu, lalu menggabungkan mereka melalui "model meta" untuk mengeluarkan hasil prediksi akhir berdasarkan hasil prediksi dari berbagai model lemah .

Metode Bagging biasanya mempertimbangkan peserta didik lemah yang homogen. Peserta didik yang lemah ini dipelajari secara paralel secara independen satu sama lain, dan mereka digabungkan menurut proses rata-rata deterministik tertentu. Dengan asumsi bahwa semua pelajar yang lemah adalah model pohon keputusan, Bagging yang dihasilkan adalah hutan acak.

Metode Boosting biasanya mempertimbangkan pelajar lemah yang homogen, tetapi idenya adalah "bagi dan taklukkan". Model ini secara berurutan mempelajari pelajar yang lemah ini dalam metode yang sangat adaptif, dan model lemah berikutnya berfokus pada mempelajari data yang salah diklasifikasikan oleh model lemah sebelumnya.
Ini setara dengan pengklasifikasi lemah yang berbeda, dengan fokus pada bagian data untuk mencapai efek "bagi dan taklukkan". Seperti yang ditunjukkan di bawah ini, Boosting adalah paradigma yang menggabungkan berbagai model secara seri. Pustaka atau algoritme XGBoost dan LightGBM yang terkenal semuanya menggunakan metode Boosting.
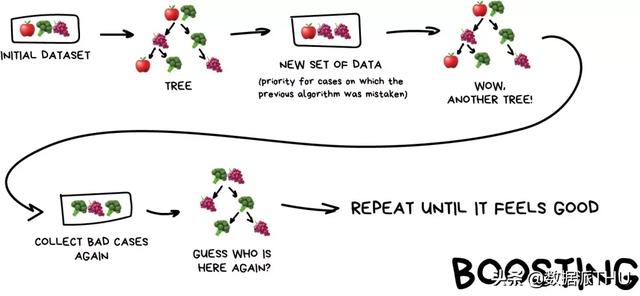
Sekarang, dari metode Naive Bayes hingga Boosting, cabang utama machine learning klasik sudah tersedia. Jika pembaca menginginkan pemahaman yang lebih sistematis dan rinci, "Metode Pembelajaran Statistik" oleh Li Hang dan "Pembelajaran Mesin" oleh Zhou Zhihua adalah dua tutorial bahasa Mandarin terbaik.
Tentunya di blog ini penulis juga memperkenalkan reinforcement learning dan deep learning dll. Konten tersebut sangat cocok bagi pembaca yang berminat pada kecerdasan buatan dan tidak ada kaitannya dengan jurusan.Dengan adanya gambar gambar tersebut dapat dikatakan sebagai ilmu yang sangat baik. Teks. Jika Anda tertarik dengan narasi yang sederhana dan mudah dipahami ini, Anda bisa membacanya secara detail di blog.
Tautan referensi: https://vas3k.com/blog/machine_learning/
-Selesai-
Ikuti platform publik WeChat resmi dari Institut Ilmu Data Tsinghua-Qingdao " Pai Data AI "Dan nomor saudara perempuan" Data Pie THU "Dapatkan lebih banyak manfaat kuliah dan konten berkualitas.