
Lei Feng.com AI Science and Technology Review: China Computer Conference CNCC 2017 yang diselenggarakan oleh Chinese Computer Society CCF dibuka pada 26 Oktober di Pusat Konvensi dan Pameran Internasional Selat Fuzhou. Ada banyak orang yang menghadiri pertemuan tersebut, dan tempat utama penuh sesak. Leifeng.com AI Technology Review juga mengirimkan tim reporter untuk berpartisipasi dalam laporan konferensi.
Setelah upacara pembukaan pada tanggal 26 pagi, sejumlah tamu undangan khusus memberikan pidato langsung dengan topik yang mencakup teknologi dan aplikasi baru dalam pengembangan ilmu komputer, keuntungan bersih bahasa alami, cara AI melayani masyarakat, dan penerapan kecerdasan buatan di platform informasi, dll. Tunggu. Li Feifei, seorang profesor di Universitas Stanford, kepala ilmuwan Google Cloud, dan salah satu tolok ukur dalam pembelajaran mesin, memberikan pidato berjudul "Visual Intelligence: Beyond ImageNet".
Li Feifei pertama kali memperkenalkan pentingnya visi pada biologi dan perkembangan pesat visi komputer dalam tugas pengenalan objek. Kemudian saya melanjutkan berdiskusi dengan Anda tentang tujuan berikutnya dari visi komputer: memperkaya pemahaman adegan, serta kemajuan dan prospek visi komputer yang dikombinasikan dengan bahasa dan visi komputer yang digerakkan oleh tugas. Pemahaman adegan dan visi komputer yang dikombinasikan dengan bahasa telah membangun jembatan antara manusia dan komputer, Visi komputer berbasis tugas juga akan bersinar di bidang robotika. Perkenalan Li Feifei tentang kerja timnya juga beragam dan menarik.

Li Feifei pertama kali memperkenalkan tonggak pertama dalam membangun kecerdasan visual, yaitu pengenalan objek. Manusia memiliki kemampuan pengenalan visual yang tak tertandingi, dan banyak penelitian oleh ahli saraf kognitif telah menunjukkan fenomena ini. Li Feifei melakukan interaksi kecil-kecilan dengan penonton di lokasi kejadian, mem-flash serangkaian foto dengan durasi hanya 0,1 detik di layar, tanpa ada penjelasan lain, dan penonton masih bisa mengenali bahwa ada seseorang di salah satu gambar tersebut.
Dalam percobaan yang dilakukan oleh profesor MIT Simon Thorpe pada tahun 1996, ia juga menunjukkan dengan merekam gelombang otak bahwa manusia hanya perlu mengamati foto yang rumit selama 150ms untuk membedakan apakah foto itu berisi hewan, apakah itu mamalia, burung, Ikan, atau serangga.

Pengenalan visual yang cepat dari objek kompleks ini adalah karakteristik dasar dari sistem visual manusia, dan ini juga merupakan "Cawan Suci" dalam visi komputer. Dalam 20 tahun terakhir, pengenalan objek telah menjadi tugas penting dalam komunitas computer vision. ImageNet adalah salah satu kumpulan data yang berkontribusi.

Sejak 2010, dari 2010 hingga 2017, tingkat kesalahan pengenalan objek dari Tantangan ImageNet telah turun menjadi sepersepuluh dari aslinya. Pada tahun 2015, tingkat kesalahan telah mencapai atau bahkan lebih rendah dari tingkat manusia. Ini pada dasarnya menunjukkan bahwa visi komputer pada dasarnya telah mengatasi masalah pengenalan objek sederhana.
Tentu saja, penelitian computer vision tidak akan berhenti di ImageNet dan pengenalan objek. Ini hanyalah dasar untuk pengalaman visual yang kaya manusia.

Langkah kunci berikutnya adalah identifikasi hubungan visual. Definisi dari tugas ini adalah: "memasukkan foto ke dalam model algoritme, dengan harapan algoritme dapat mengidentifikasi objek utama, menemukan lokasinya, dan menemukan hubungan berpasangan di antara objek tersebut."
Kedua foto tersebut adalah orang dan alpacas, tetapi yang terjadi sama sekali berbeda. Inilah yang tidak bisa dijelaskan oleh pengenalan objek belaka.

Sebelum era deep learning terdapat banyak penelitian di bidang ini, namun sebagian besar hanya dapat menganalisis beberapa hubungan seperti hubungan spasial, hubungan tindakan, dan hubungan sejenis dalam ruang yang dikendalikan oleh manusia. Dengan ledakan daya komputasi dan volume data, para peneliti akhirnya dapat membuat kemajuan besar di era pembelajaran yang mendalam. Ini membutuhkan kombinasi representasi visual dari jaringan saraf konvolusional dan model bahasa.
Dalam makalah yang disertakan dalam ECCV2016 oleh tim Li Feifei, model mereka sudah dapat memprediksi hubungan spasial, hubungan perbandingan, hubungan semantik, hubungan tindakan, dan hubungan posisi. Selain "mencantumkan semua objek", mereka bergerak menuju pemahaman yang kaya tentang hubungan antar objek di tempat kejadian. Sebuah langkah yang solid telah diambil.

Selain prediksi hubungan, pembelajaran bebas sampel juga dapat dilakukan. Misalnya, gunakan foto orang yang duduk di kursi untuk melatih sang model, ditambah foto hidran di tanah. Kemudian ambil gambar lainnya, duduk sendirian di hidran. Meskipun algoritme belum melihat gambar ini, algoritme dapat menyatakan bahwa ini adalah "seseorang yang duduk di hidran kebakaran".

Demikian pula, algoritme dapat mengenali "kuda bertopi", meskipun hanya ada gambar "orang yang menunggang kuda" dan "orang bertopi" di set pelatihan.

Setelah makalah ECCV 2016 tim Li Feifei, sejumlah besar makalah terkait diterbitkan tahun ini, beberapa di antaranya bahkan melebihi performa model mereka. Ia juga sangat senang melihat kemakmuran dan perkembangan penelitian terkait tugas ini.
Setelah masalah pengenalan objek sebagian besar diselesaikan, tujuan Li Feifei selanjutnya adalah keluar dari objek itu sendiri. Kumpulan data Microsoft's Coco tidak lagi berupa gambar + label, tetapi gambar + kalimat pendek yang menjelaskan konten utama gambar.
Setelah tiga tahun persiapan, tim Li Feifei meluncurkan dataset Visual Genome, yang berisi 100.000 gambar, 4.2 juta deskripsi gambar, 1,8 juta pasangan tanya jawab, 1,4 juta objek yang diberi tag, 1,5 juta hubungan, dan 1,7 juta. Atribut artikel. Ini adalah kumpulan data yang sangat kaya. Tujuannya adalah untuk keluar dari objek itu sendiri dan fokus pada hubungan, bahasa, penalaran, dll. Antara objek yang lebih luas.


Setelah dataset Genome Visual, studi lain yang dilakukan oleh tim Li Feifei adalah untuk memahami kembali pengenalan adegan.
Pengenalan adegan saja adalah tugas yang sederhana. Pencarian "pria berjas" atau "anak anjing lucu" di Google akan mendapatkan hasil yang diinginkan secara langsung.

Namun saat Anda menelusuri "pria berjas menggendong anak anjing yang lucu", Anda tidak akan mendapatkan hasil yang baik. Kinerjanya menjadi lebih buruk di sini, dan hubungan antar objek semacam ini adalah hal yang sulit untuk ditangani.

Jika Anda hanya fokus pada pengenalan objek "bangku" dan "orang", Anda tidak akan mendapatkan hubungan "orang yang duduk di bangku", bahkan jika jaringan dilatih untuk mengenali "orang yang duduk", tidak dapat dijamin untuk melihat gambaran keseluruhan.

Mereka memiliki ide untuk memasukkan semua hubungan di luar objek dan di dalam adegan, dan kemudian menemukan cara untuk mengekstrak hubungan yang tepat.

Jika terdapat grafik adegan (grafik) yang berisi berbagai informasi semantik kompleks dalam adegan tersebut, maka pengenalan pemandangan dapat dilakukan dengan lebih baik. Mungkin sulit untuk mendeskripsikan semua detail dalam kalimat yang panjang, tetapi setelah mengubah kalimat panjang menjadi grafik pemandangan, kita dapat membandingkannya dengan gambar menggunakan metode yang berhubungan dengan grafik; grafik pemandangan juga dapat dikodekan sebagai bagian dari database, dari Kueri dari perspektif database.

Tim Li Feifei telah menggunakan teknologi pencocokan grafik adegan untuk mendapatkan banyak hasil kuantitatif yang baik dalam adegan yang mengandung banyak informasi semantik. Tapi siapa yang mendefinisikan grafik pemandangan ini? Dalam kumpulan data Genom Visual, semua grafik adegan ditentukan secara manual. Entitas, struktur, hubungan antara entitas, dan pencocokan gambar semuanya dilakukan secara manual oleh tim Li Feifei. Prosesnya menyakitkan, dan mereka tidak ingin memperbaikinya di masa mendatang. Setiap adegan melakukan pekerjaan seperti ini. Jadi setelah pekerjaan ini, mereka juga mengalihkan perhatian mereka ke pembuatan grafik pemandangan otomatis.

Misalnya, makalah CVPR2017 yang dia dan siswanya selesaikan bersama ini adalah skema untuk menghasilkan grafik scene secara otomatis. Untuk citra input, pertama-tama dapatkan kandidat hasil pengenalan objek, kemudian gunakan algoritma penalaran grafik untuk mendapatkan hubungan antara entitas dan entitas. Hubungan dan sebagainya; proses ini dilakukan secara otomatis.

Beberapa algoritma transfer informasi berulang dilibatkan di sini, dan Li Feifei tidak menjelaskan secara rinci. Namun hasil ini menunjukkan bahwa ada banyak kesamaan antara cara kerja model ini dan apa yang dilakukan orang.

Ini mewakili serangkaian kemungkinan baru yang datang kepada umat manusia. Dengan bantuan grafik pemandangan, kita dapat mengekstrak informasi, memprediksi hubungan, memahami korespondensi, dan sebagainya.

Masalah QA juga telah diselesaikan dengan lebih baik.

Tujuan penelitian lainnya adalah memberikan gambaran keseluruhan paragraf teks eksplanasi.
Ketika Li Feifei adalah seorang mahasiswa PhD di California Institute of Technology, dia melakukan percobaan di mana orang-orang diminta untuk mengamati sebuah gambar dan kemudian meminta mereka untuk mengatakan sebanyak mungkin apa yang mereka lihat dalam gambar tersebut. Saat melakukan percobaan, sebuah foto berkedip cepat pada layar di depan subjek, kemudian ditutup dengan gambar lain atau gambar seperti wallpaper, fungsinya untuk menjernihkan informasi yang tertinggal di retina mereka.
Kemudian biarkan mereka menuliskan sebanyak mungkin apa yang mereka lihat. Dari hasil yang didapat, beberapa foto tampak lebih mudah, namun kenyataannya hanya karena kami telah memilih lama waktu tampilan yang berbeda. Foto terpendek hanya ditampilkan 27 milidetik, yang sudah mencapai batas atas kecepatan tampilan monitor saat itu; beberapa foto menunjukkan 0,5 Detik lebih dari cukup untuk pemahaman visual manusia.

Untuk foto ini, konten yang bisa dilihat dalam waktu singkat juga sangat terbatas, dan mereka bisa menulis paragraf panjang dalam 500 milidetik. Evolusi telah memberi kita kemampuan untuk menceritakan sebuah cerita panjang hanya dengan melihat gambar.
Dalam 3 tahun terakhir, para peneliti di bidang CV telah mempelajari cara mengubah informasi dalam gambar menjadi cerita.

Mereka pertama kali mempelajari deskripsi gambar, seperti menggunakan CNN untuk merepresentasikan konten gambar dalam ruang fitur, dan kemudian menggunakan RNN seperti LSTM untuk menghasilkan serangkaian teks. Jenis pekerjaan ini memiliki banyak hasil sekitar tahun 2015, dan sejak itu kami dapat membuat komputer mencocokkan hampir semua hal dengan kalimat.

Ambil dua contoh ini, "Seorang pekerja dengan rompi oranye sedang membuka jalan" dan "Seorang pria berkemeja hitam sedang memainkan gitar."


Ini adalah hasil CVPR2015. Dua tahun kemudian, algoritme tim Li Feifei bukan lagi yang paling canggih, tetapi memang salah satu karya pionir di bidang penjelasan gambar.
Terus lakukan penelitian ke arah tersebut.Hasil selanjutnya yang mereka usulkan adalah uraian yang padat, yaitu banyak area dalam sebuah gambar yang akan mengalokasikan perhatian, sehingga bisa terdapat banyak kalimat berbeda yang menggambarkan area yang berbeda, tidak hanya Hanya satu kalimat yang menggambarkan seluruh adegan. Kombinasi model CNN dan model deteksi wilayah logis digunakan di sini, ditambah model bahasa, sehingga pemandangan dapat diberi label dengan rapat.

Misalnya, gambar ini dapat dihasilkan, "Ada dua orang duduk di kursi", "Ada gajah", "Ada pohon", dll.

Foto dalam ruangan lain dari siswa Li Feifei juga menandai konten yang kaya.

Dalam penelitian CVPR2017 baru-baru ini, mereka membawa kinerja ke tingkat yang baru, tidak hanya sekadar kalimat penjelas, tetapi juga menghasilkan paragraf teks, menghubungkannya dengan cara yang bermakna spasial. Dengan cara ini, kita dapat menulis "jerapah berdiri di dekat pohon dengan tiang dengan daun di sisi kanannya, dan bangunan bata hitam putih di belakang pagar", dan seterusnya. Meskipun ada kesalahan di dalamnya dan ini jauh lebih sedikit daripada karya Shakespeare, kami telah mengambil langkah pertama dalam menggabungkan visi dan bahasa.

Apalagi perpaduan antara visi dan bahasa tidak berhenti pada citra diam, hanya salah satu capaian terkini. Dalam studi lain, mereka menggabungkan video dan bahasa.

Sebagai contoh, penelitian CVPR2017 ini dapat melakukan joint reasoning dan memilah struktur teks dari berbagai bagian dalam sebuah video penjelasan. Kesulitannya di sini adalah mengurai entitas dalam teks. Misalnya, langkah pertama adalah "mengaduk sayuran" lalu "mengeluarkan campuran". Jika algoritme dapat menguraikan bahwa "campuran" mengacu pada sayuran yang dicampur pada langkah sebelumnya, itu akan bagus.

Setelah bahasa tersebut, Li Feifei juga memperkenalkan masalah penglihatan berdasarkan tugas. Untuk seluruh keluarga penelitian AI, AI yang digerakkan oleh tugas adalah mimpi jangka panjang yang umum. Sejak awal, manusia berharap menggunakan bahasa untuk memberikan instruksi kepada robot, dan kemudian robot menggunakan metode visual untuk mengamati dunia, memahami, dan menyelesaikan tugas.
Ini adalah masalah klasik yang didorong oleh tugas. Manusia berkata: "Piramida biru itu bagus. Saya suka kubus yang tidak berwarna merah, tapi saya tidak suka apa pun dengan 5-hedron. Apakah saya suka kotak abu-abu? "Kemudian mesin, atau robot, atau agen akan menjawab:" Tidak, karena itu dilapisi dengan 5-hedron. " Itu digerakkan oleh tugas, untuk memahami dan bernalar tentang dunia yang kompleks ini.

Tim Li Feifei bekerja dengan Facebook untuk meneliti ulang masalah tersebut, membuat pemandangan dengan berbagai benda geometris, dan kemudian mengajukan pertanyaan kecerdasan buatan untuk melihat bagaimana ia akan memahami, menalar, dan memecahkan masalah ini. Ini akan melibatkan identifikasi, penghitungan, perbandingan, hubungan spasial dan sebagainya dari atribut.

Makalah pertama di bidang ini menggunakan model perhatian CNN + LSTM +. Hasilnya lumayan. Manusia dapat mencapai tingkat yang benar lebih dari 90%. Meskipun mesin dapat mencapai mendekati 70%, masih ada celah yang sangat besar. Kesenjangan ini karena manusia dapat menggabungkan penalaran, tetapi mesin tidak bisa.

Di ICCV, mereka memperkenalkan hasil makalah baru. Dengan bantuan kumpulan data CLEVR baru, masalah diuraikan menjadi segmen program dengan fungsi, dan kemudian mesin eksekusi yang dapat menjawab pertanyaan dilatih berdasarkan segmen program. Skema ini memiliki kemampuan kombinatorial yang jauh lebih tinggi ketika mencoba bernalar tentang masalah dunia nyata.
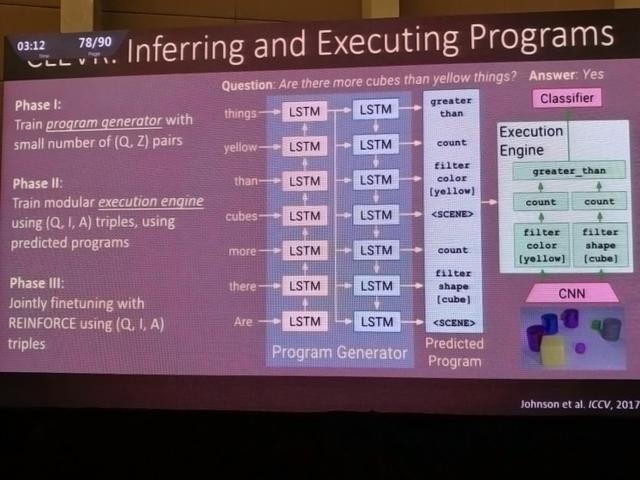
Dalam pengujian, itu akhirnya melebihi kinerja manusia.

Performa model yang sebenarnya pasti bagus. Misalnya, dalam contoh ini, jika kita bertanya apa bentuk warna tertentu, ia akan menjawab "itu adalah kubus", yang menunjukkan bahwa alasannya benar. Itu juga bisa menghitung jumlah hal. Semua ini menunjukkan bahwa algoritme dapat bernalar tentang adegan tersebut. Peta panas juga menunjukkan bahwa model fokus dengan benar pada area di peta.

Setelah berbicara banyak tentang tugas yang berhubungan dengan gambar, Li Feifei merangkumnya ke dalam dua kategori
-
Yang pertama adalah pengenalan hubungan, representasi semantik kompleks, dan grafik pemandangan selain pengenalan objek;
-
Di luar inti adegan, kita perlu menggunakan bahasa visi + untuk memproses anotasi kalimat tunggal, pembuatan paragraf, pemahaman video, dan penalaran bersama;

Li Feifei akhirnya menunjukkan foto putrinya yang baru berusia 20 bulan, namun kemampuan visualnya juga menjadi bagian penting dari kesehariannya. Membaca, melukis, mengamati emosi, dll., Kemajuan besar ini merupakan penelitian masa depan di bidang ini. tujuan.

Kecerdasan visual adalah langkah kunci dalam pemahaman, komunikasi, kerjasama, interaksi, dll. Eksplorasi manusia di bidang ini baru saja dimulai.

(Selesai)
CNCC2017 masih dalam proses, harap nantikan tindak lanjut laporan luar biasa dari Leifeng.com AI Technology Review.