Sedikit dari candi cekung Laporan Qubit | Akun Publik QbitAI
Pada 9 April, Nvidia x Qubit membagikan kursus online nlp. Xue Boyang, pakar komputasi GPU dari NVIDIA dan salah satu pengembang FasterTransformer 2.0, berdiskusi dengan ratusan pengembang:
- Pengenalan fitur baru FasterTransformer 2.0
- Cara mengoptimalkan Decoder dan Decoding
- Cara menggunakan Decoder dan Decoding
- Jenis efek akselerasi apa yang dapat diberikan Decoder dan Decoding?
Atas permintaan pembaca, kami akan memilah konten yang dibagikan dan belajar dengan semua orang. Di akhir artikel terdapat link ke siaran langsung dan PPT ini, yang juga bisa anda tonton secara langsung.
Berikut adalah konten sharing ini:
Halo semuanya, hari ini saya akan memperkenalkan kepada Anda Prinsip dan penerapan FasterTransformer 2.0 .
Apa itu FasterTransformer?
Pertama-tama, teman-teman yang berpartisipasi dalam siaran langsung ini harus memiliki pemahaman tertentu tentang arsitektur Transformer. Arsitektur ini diusulkan dalam makalah "Attention is All You Need". Banyak Transformer digunakan di BERT Encoder, dan efeknya sangat bagus. Oleh karena itu, Transformer telah menjadi arsitektur jaringan pembelajaran mendalam yang sangat populer di bidang NLP.
Namun perhitungan Transformer biasanya sangat besar. Oleh karena itu, keterlambatan Trafo seringkali sulit untuk memenuhi kebutuhan aplikasi praktis.

Perhatian adalah Semua yang Anda Butuhkan tangkapan layar
Arsitektur transformator dapat diterapkan pada Encoder atau Decoder. Di dalam Encoder, Transformer berisi 1 multi-head attention dan 1 feed forward network, pada Decoder berisi 2 multi-head attention dan 1 feed forward network.
Diantaranya, arsitektur Encoder murni memiliki performa yang baik di banyak aplikasi saat ini, seperti sistem QA, sistem rekomendasi periklanan, dll. Oleh karena itu, optimasi Encoder sangat diperlukan.
Dalam beberapa skenario, seperti skenario terjemahan, kita membutuhkan arsitektur Encoder dan Decoder. Di bawah arsitektur ini, proporsi waktu yang dikonsumsi oleh decoder sangat tinggi, yang dapat mencapai lebih dari 90%, yang merupakan hambatan utama dalam penalaran. Oleh karena itu, pengoptimalan decoder juga merupakan pekerjaan penting, yang dapat memberikan efek akselerasi yang jelas.
Dalam aplikasi praktis, FasterTransformer versi 1.0 telah melakukan banyak optimasi dan akselerasi untuk Encoder di BERT. Dalam versi 2.0, pengoptimalan untuk Decoder terutama ditambahkan, dan performa superiornya akan membantu berbagai skenario generatif seperti terjemahan, robot dialog, penyelesaian teks, dan koreksi.

Tabel di atas membandingkan jumlah perhitungan Encoder dan Decoder. Saat kita perlu menyandikan dan mendekode kalimat, Pembuat Enkode dapat menyandikan banyak kata pada saat yang sama, atau bahkan langsung menyandikan kalimat.
Tetapi Decoder adalah proses decoding, dan hanya satu kata yang dapat didekodekan dalam satu waktu. Oleh karena itu, kita memerlukan beberapa Decoder ke depan saat mendekode kalimat, yang bahkan lebih tidak bersahabat dengan GPU.

Kerangka Transformer Lebih Cepat
Gambar di atas mencantumkan modul yang dioptimalkan untuk BERT di FasterTransformer. Dalam hal pengkodean, berdasarkan BERT, modul lapisan tunggal yang setara dengan BERT Transformer disediakan bagi pengguna untuk dipanggil. Saat kita membutuhkan Transformer multi-layer, kita hanya perlu memanggil Encoder beberapa kali.
Penguraian kode lebih rumit. Untuk menyeimbangkan fleksibilitas dan efisiensi, kami menyediakan dua modul dengan ukuran dan efek yang berbeda:
Decoder (blok kuning) terdiri dari layer Transformer single-layer, yang berisi dua jaringan perhatian dan feed forward; dan Decoding (blok biru) selain mengandung beberapa lapisan layer Transformer, juga mencakup fungsi lain, seperti embedding_lookup, beam search, encoding posisi, dll.

Kami menggunakan kode dummy sederhana untuk menunjukkan perbedaan antara Decoder dan Decoding.
Biasanya ada dua kondisi terminasi dalam Decoding, yang pertama adalah apakah panjang urutan maksimum tercapai terlebih dahulu, dan kondisi kedua adalah apakah semua kalimat telah diterjemahkan, dan akan terus berputar ketika tidak diakhiri.
Ambil skenario terjemahan kalimat dengan panjang kalimat 128 sebagai contoh. Jika Decoder-nya terdiri dari 6 lapisan lapisan Transformer, total 128x6 = 768 Decoder perlu dipanggil; jika Decoding digunakan, Decoding hanya perlu dipanggil sekali, jadi Decoding Efisiensi penalaran lebih tinggi.
ringkasan

Pertama-tama, FasterTransformer menyediakan lapisan Transformer yang sangat dioptimalkan: didasarkan pada BERT untuk Encoder; ini didasarkan pada pustaka open source OpenNMT-TensorFlow sebagai standar untuk Decoder; Dekode berisi seluruh proses terjemahan dan juga didasarkan pada OpenNMT-TensorFlow.
Kedua, lapisan bawah FasterTransformer 2.0 diimplementasikan oleh CUDA dan cuBLAS, mendukung dua mode kalkulasi FP16 dan FP32, dan saat ini menyediakan C ++ API dan TF OP.
Sekarang, FasterTransformer 2.0 adalah open source. Anda bisa mendapatkan semua kode sumber di DeepLearningExamples / FasterTransformer / v2 di master · NVIDIA / DeepLearningExamples · GitHub.
Bagaimana cara mengoptimalkan?
Mari kita ambil Encoder sebagai contoh.

Lapisan Transformator Encoder TF
Parameter: tanpa XLA, ukuran batch 1, 12 kepala, ukuran per kepala 64, FP 32
Kotak biru pada gambar menunjukkan bahwa GPU benar-benar berjalan, dan kotak kosong menunjukkan bahwa GPU menganggur, sehingga GPU menganggur beberapa kali. Alasan GPU menganggur adalah karena kernel terlalu kecil, dan GPU harus terus-menerus diam untuk menunggu waktu CPU memulai kernel. Ini juga disebut masalah terkait peluncuran kernel.
bagaimana mengatasi masalah ini?

Kami mencoba membuka XLA TF, parameter lain tetap tidak berubah. Pada gambar, kita dapat melihat bahwa dari perhitungan asli lapisan lapisan Transformer, 50 kernel harus dikurangi menjadi sekitar 24. Sebagian besar kernel menjadi lebih lebar meskipun ada akselerasi, namun waktu idle masih lebih banyak.

Oleh karena itu, kami mengusulkan FasterTransformer untuk mengoptimalkan Encoder.
Pertama-tama, kami memilih bagian kalkulasi matriks dan menggunakan library cuBLAS NVIDIA yang sangat dioptimalkan untuk menghitung. Untuk bagian lainnya, kami mengintegrasikan kernel yang dapat diintegrasikan sebanyak mungkin.
Hasil akhirnya seperti yang terlihat pada gambar di atas. Setelah optimasi secara keseluruhan, kita hanya membutuhkan 8 perhitungan matriks ditambah 6 kernel untuk menyelesaikan perhitungan lapisan Transformer satu lapis, yang berarti kernel yang dibutuhkan berkurang dari 24 menjadi 14.

Kita dapat melihat bahwa setelah optimasi, setiap kernel relatif besar, dan kernel dengan proporsi waktu yang kecil juga berkurang. Tapi masih banyak fragmen kosong.

Kami langsung memanggil C ++ API, seperti yang ditunjukkan pada gambar, waktu idle GPU hampir habis. Oleh karena itu, dalam kasus ukuran tumpukan kecil, kami merekomendasikan penggunaan C ++ API untuk kecepatan yang lebih cepat. Jika ukuran batch relatif besar, waktu idle GPU akan lebih sedikit.
Selanjutnya kita melihat Decoder.

Parameter: tanpa XLA, ukuran batch 1, 8 kepala, ukuran per kepala 64, FP32
Menurut statistik, TF perlu menggunakan sekitar 70 kernel untuk menghitung lapisan Transformer. Secara intuitif, ada lebih banyak kernel yang sangat kecil dan memiliki rasio waktu yang sangat singkat. Oleh karena itu, jika ukuran batch relatif kecil, efek pengoptimalan akan lebih terlihat.
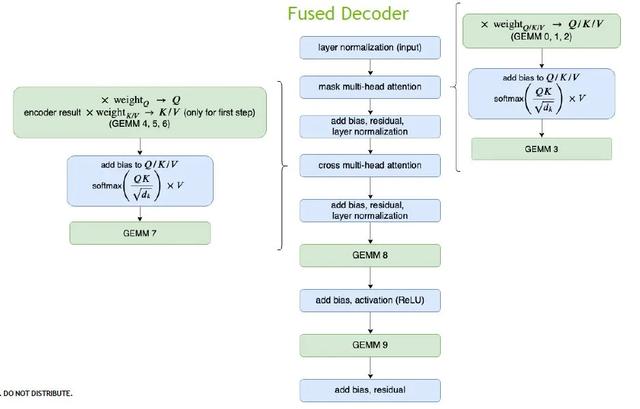
Pengoptimalan Decoder sama dengan Encoder di atas.Fitur khusus adalah bahwa jumlah perhitungan matriks dalam Decoder sangat kecil, jadi kami menggunakan satu kernel untuk menyelesaikan seluruh perhatian multi-head. Setelah pengoptimalan, kalkulasi yang awalnya membutuhkan 70 kernel untuk diselesaikan dapat diselesaikan hanya dengan 16 kernel.

Dalam modul Decoding yang lebih besar, kernel lain yang menghabiskan lebih banyak waktu adalah pencarian berkas. Di sini kita mengoptimalkan k teratas. Di GPU, banyak blok dan banyak lengkungan dapat dieksekusi pada saat yang sama, operasi paralel, sangat menghemat waktu.

Detail yang lebih optimal
Bagaimana cara menggunakan FasterTransformer?
Anda dapat menemukan informasi terkait di DeepLearningExamples / FasterTransformer / v2 di master · NVIDIA / DeepLearningExamples · direktori root GitHub:



Untuk Decoder dan Decoding, FasterTransformer masing-masing menyediakan C ++ dan TensorFlow OP.
Antarmuka C ++
Pertama buat Eecoder, hyperparameternya ditunjukkan pada gambar:

Kedua, setel bobot model yang dilatih;
Setelah pengaturan, panggil saja langsung.
Antarmuka TF OP
Pertama, kita perlu memuat OP terlebih dahulu. Mengambil Decoder sebagai contoh, pustaka yang dibutuhkan oleh TF akan dibuat secara otomatis, dan file .so (ditandai dengan warna merah pada gambar) akan diimpor terlebih dahulu saat memanggil antarmuka:

Kemudian panggil Decoder, masukkan input, weight, dan hyperparameter, lalu lakukan Session run for out put.
Perlu dicatat di sini bahwa ada input pseudo dalam parameter. Masukan ini untuk menghindari paralelisasi dekoder TensorFlow dan Dekoder FasterTransformer, karena kami menemukan bahwa memori di dekoder mungkin terkontaminasi saat dijalankan secara paralel. Masukan ini dapat dihapus dalam aplikasi sebenarnya.
Efek pengoptimalan
Terakhir, mari kita lihat efek pengoptimalan. Pertama uji pengaturan lingkungan:

GPU yang digunakan adalah Tesla T4 dan V100 milik NVIDIA.
Hasil modul Encoder di Tesla V100
Pengaturan parameter hyper: 12 lapisan, 32 panjang urutan, 12 kepala, 64 ukuran per kepala (basis BERT), di bawah FP 16

Hasilnya seperti gambar di atas: Dalam proses peningkatan ukuran batch secara bertahap dari 100 menjadi 500, FasterTransformer dibandingkan dengan TF dan menyalakan XLA, yang dapat memberikan akselerasi sekitar 1,4 kali lipat.
Hasil modul Decoder dan Decoding pada Tesla T4
Pengaturan hyper-parameter: Ukuran batch 1, lebar berkas 4, 8 kepala, 64 ukuran per kepala, 6 lapisan, ukuran kosakata 30000, FP 32

Hasilnya seperti gambar di atas: Dibandingkan dengan TF, FasterTransformer Decoder mampu menghasilkan akselerasi sekitar 3,4 kali lipat, dan Decoding mampu menghasilkan akselerasi 7-8 kali lipat, yang lebih efisien.
Pengaturan hyper-parameter: Ukuran batch 256, panjang urutan 32, lebar balok 4, 8 kepala, 64 ukuran per kepala, 6 lapisan, ukuran kosakata 30000

Hasilnya seperti yang ditunjukkan pada gambar di atas: Ketika ukuran batch ditetapkan pada nilai yang lebih tinggi, FasterTransformer Decoder dan Decoding juga membawa efek akselerasi tertentu di bawah FP yang berbeda.
Terakhir, PPT siaran langsung ini mendapatkan koneksi: "Tautan"
Putar ulang siaran langsung ini: NVIDIA Webinar